Core idea

Users are allowed to feed multiple inputs (e.g., a single image for character, a pose sequence for motion, and a single video/image for scene) to provide desired attributes respectively or a direct driving video as input. The proposed model can embed target attributes into the latent space to construct target codes and encode the driving video with spatial-aware decomposition as spatial codes, thus enabling intuitive attribute control of the synthesis by freely integrating latent codes in a specific order.
Method
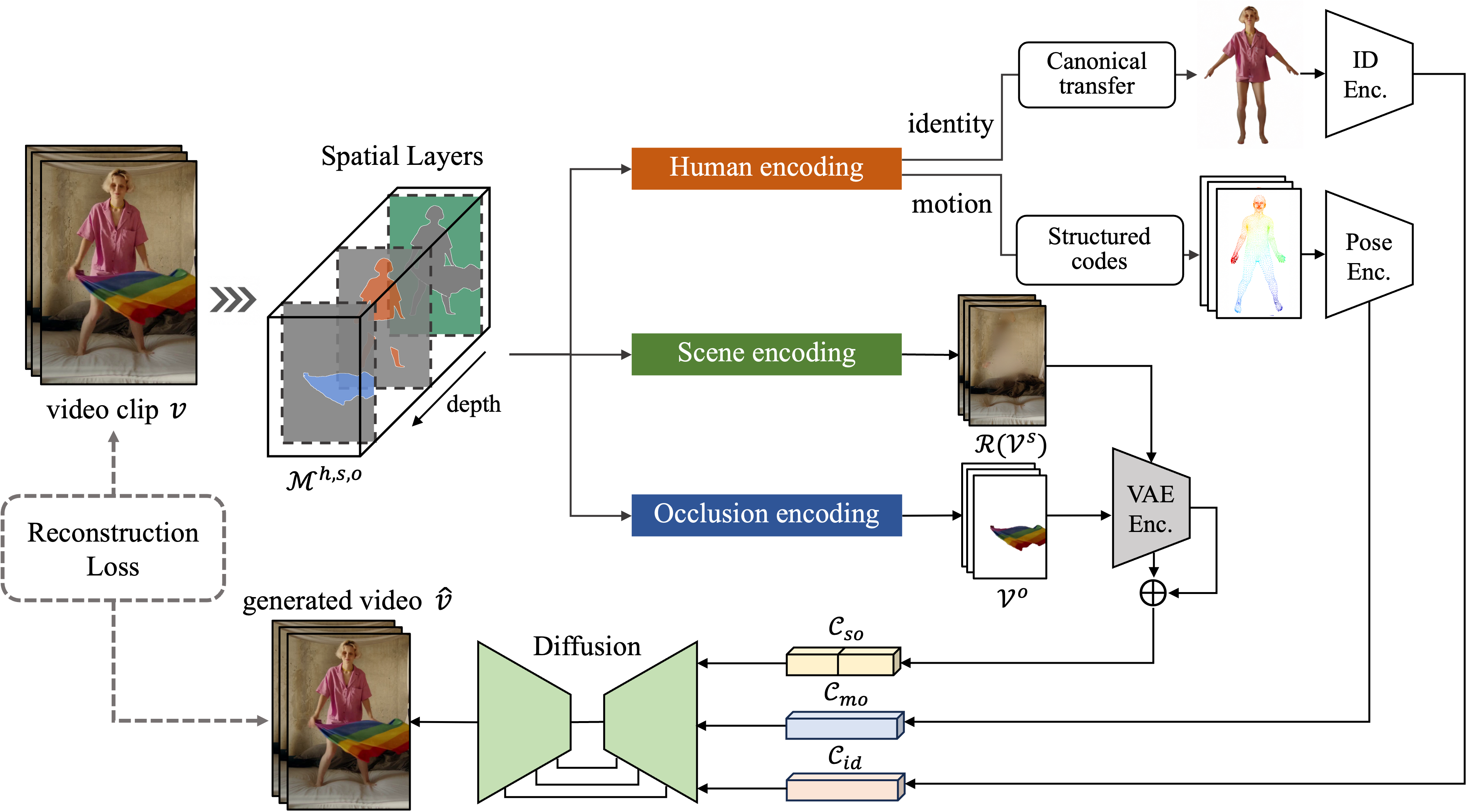
An overview of the proposed framework. The video clip is decomposed to three spatial components (i.e., main human, underlying scene, and floating occlusion) in hierarchical layers based on 3D depth. The human component is further disentangled for properties of identity and motion via canonical appearance transfer and structured body codes, and encoded to identity code $\mathcal{C}_{id}$ and motion code $\mathcal{C}_{mo}$. The scene and occlusion components are embedded with a shared VAE encoder and re-organized as a full scene code $\mathcal{C}_{so}$. These latent codes are inserted into a diffusion-based decoder as conditions for video reconstruction.
Results
Arbitrary Character Control
Animating human, cartoon or personified ones from a single image
Novel 3D Motion Control
Complex motions from in-the-wild videos
Spatial 3D motions from the database
Interactive Scene Control
Complicated real-world scenes with object interaction accompanied by occlusions
Comparisons
Compared with SOTA 2D methods
Compared with SOTA 3D methods
Demo Video
Citation
@article{men2024mimo,
title={MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling},
author={Men, Yifang and Yao, Yuan and Cui, Miaomiao and Liefeng, Bo},
booktitle={arXiv preprint arXiv:2409.16160},
year={2024}
}